The Great CrowdStrike Meltdown: When Cybersecurity Became the Threat
Explore the far-reaching consequences of the CrowdStrike update mishap, its global impact on various industries, and the crucial lessons learned for the future of cybersecurity.

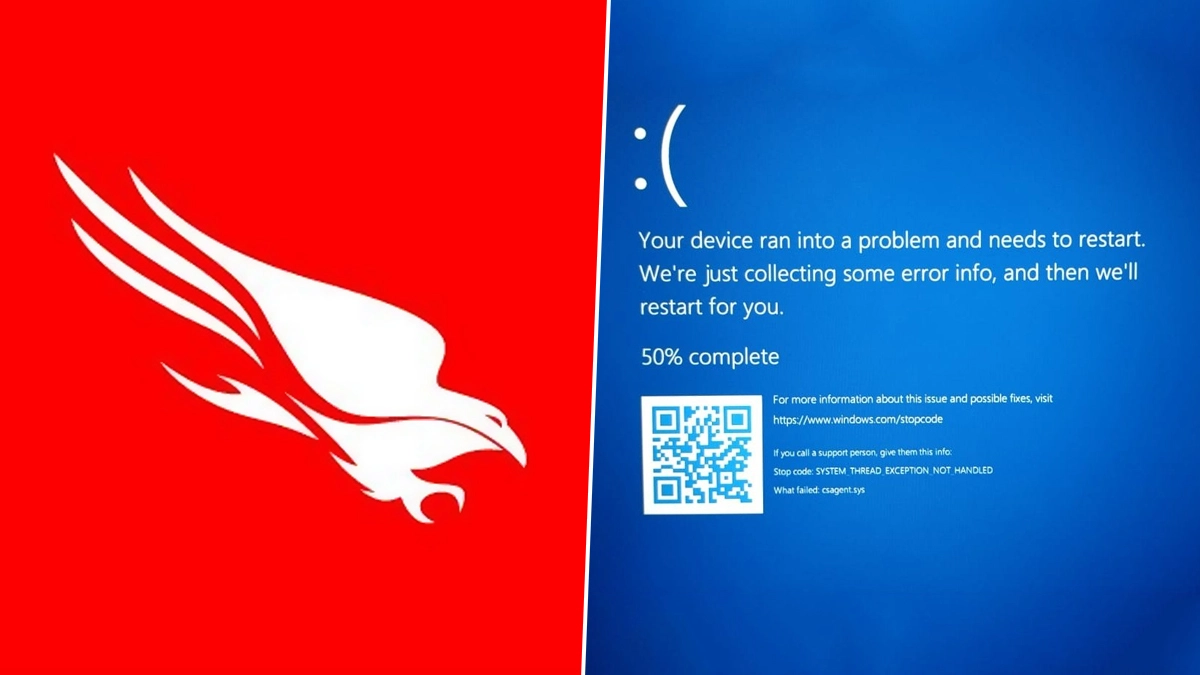
In the ever-evolving landscape of technology, we’ve witnessed numerous incidents that have shaken the digital world to its core. However, few can compare to the recent CrowdStrike incident - a event that will be remembered as one of the most significant technological disruptions of our time. What began as a routine software update quickly spiraled into a global crisis, affecting millions of computers worldwide and bringing countless organizations to their knees.
The Incident Unfolds
It all started with a seemingly innocuous post on the CrowdStrike subreddit. “BSOD error in the latest CrowdStrike update,” the title read. Within hours, this lone voice became a chorus as reports flooded in from around the globe. Computers were stuck in boot loops, unable to progress past the dreaded Blue Screen of Death (BSOD). But this wasn’t just affecting a handful of unlucky users – entire organizations found themselves paralyzed.
The Scope of the Disaster
As the situation unfolded, the true scale of the catastrophe began to emerge. Airports ground to a halt, with staff resorting to handwritten boarding passes. Banks shuttered their digital operations, unable to process transactions. Hospitals struggled to access patient records, potentially putting lives at risk. Government agencies found themselves locked out of critical systems. Even supermarkets were forced to accept only cash as their point-of-sale systems went dark.
The irony was lost on no one – a tool designed to protect against cyber threats had become the biggest threat of all. CrowdStrike’s Falcon, a widely-used endpoint protection platform, had inadvertently brought down the very systems it was meant to safeguard.
Understanding CrowdStrike Falcon
To comprehend how this disaster occurred, we need to understand what CrowdStrike Falcon is and how it operates. Falcon is an endpoint detection and response (EDR) tool that provides real-time protection against cyber threats. Unlike traditional antivirus software that runs after a computer starts up, Falcon operates at a deeper level, integrating directly with the operating system.
Falcon uses kernel-mode drivers to gain low-level access to the system, allowing it to monitor and protect against threats more effectively. This approach, while powerful, also means that any issues with Falcon can have severe consequences for the entire system.
The Root of the Problem
At the heart of this chaos was a faulty update pushed out by CrowdStrike. The update contained a driver file that was essentially empty – filled with zeros instead of the expected code. When systems attempted to load this corrupted driver, they inevitably crashed, unable to boot properly.
What made this situation particularly dire was CrowdStrike’s update mechanism. To stay ahead of emerging cyber threats, CrowdStrike uses a system of over-the-air (OTA) updates. This means that many devices received the faulty update automatically, without any user intervention. As a result, countless machines were bricked overnight, their users waking up to find their computers unusable.
The Global Impact
The consequences of this incident were far-reaching and severe. Let’s break down some of the most significant impacts:
-
Aviation Industry: Numerous airports worldwide faced major disruptions. Flight information displays showed the Windows blue screen, check-in systems were down, and air traffic control faced significant challenges. This led to widespread flight cancellations and delays, stranding thousands of travelers.
-
Financial Sector: Banks and stock exchanges faced severe disruptions. ATMs were out of service, online banking platforms were inaccessible, and trading floors ground to a halt. The economic impact of this downtime is still being calculated, but it’s expected to be in the billions.
-
Healthcare: Hospitals and clinics struggled to access electronic health records, schedule appointments, and operate critical equipment. In some cases, this led to the postponement of non-emergency procedures and created significant risks for patient care.
-
Retail: Many stores and supermarkets were forced to revert to cash-only transactions as their point-of-sale systems went down. This not only inconvenienced customers but also highlighted our dependence on digital payment systems.
-
Government Services: Various government agencies found their operations crippled. From local municipalities to national-level departments, the ability to provide services to citizens was severely impacted.
-
Corporate World: Countless businesses, from small startups to multinational corporations, found themselves unable to operate. With employees unable to access their workstations, productivity plummeted, and financial losses mounted by the hour.
The Technical Nightmare of Fixing the Problem
The solution to this problem, while conceptually simple, proved to be a logistical nightmare. It involved booting affected systems in safe mode, manually deleting the corrupted driver file, and then rebooting. However, this process was complicated by several factors:
-
Scale: The sheer number of affected devices meant that IT departments were overwhelmed, unable to quickly address all impacted systems.
-
Lack of User Permissions: Many users, especially in corporate environments, lack the necessary permissions or knowledge to boot into safe mode and modify system files.
-
BitLocker Complications: Systems using BitLocker encryption faced additional hurdles. Safe mode often can’t connect to networks to retrieve decryption keys, making it difficult to access the system even in this limited state.
-
Remote Work Challenges: With many employees working remotely, IT departments faced the added challenge of trying to guide users through complex troubleshooting steps over the phone or via remote sessions.
-
Interdependencies: In many cases, the servers that would typically assist in recovery (such as those hosting BitLocker keys) were themselves affected by the issue, creating a catch-22 situation.
The Community Response
In the face of this crisis, the tech community rallied. Forums and chat rooms buzzed with activity as sysadmins and cybersecurity experts shared theories and potential fixes. It was like watching a global hackathon unfold in real-time, with the stakes higher than ever.
Various workarounds emerged, from booting into safe mode and manually deleting files to more complex solutions involving bootable USB drives. The community’s response showcased the incredible problem-solving potential of crowdsourced solutions in times of crisis.
CrowdStrike’s Response and Public Relations Challenge
CrowdStrike’s response to the crisis was swift but not without controversy. The company quickly acknowledged the issue and mobilized its team to develop a fix. However, their initial communications were criticized for lacking empathy and failing to fully grasp the scale of the problem.
The company’s CEO released a statement that, while factually informative, was perceived by many as tone-deaf to the immense disruption caused. This highlighted the importance of crisis communication in the tech industry, especially when dealing with incidents of this magnitude.
As the crisis unfolded, CrowdStrike faced a significant public relations challenge. They needed to balance transparency about the issue with maintaining confidence in their product. The incident raised questions about the company’s testing procedures and the wisdom of their automatic update system.
Lessons Learned and Future Implications
This incident serves as a stark reminder of several crucial points in our increasingly digital world:
-
The Double-Edged Sword of Centralization: While centralized security solutions offer powerful protection, they also create a single point of failure that can have catastrophic consequences. This incident has sparked debates about the wisdom of relying so heavily on a single security provider across critical infrastructure.
-
The Importance of Robust Testing: No matter how trusted a software provider is, thorough testing of updates is crucial before widespread deployment. This event will likely lead to industry-wide reassessment of update procedures, especially for critical systems.
-
The Need for Diversification: Relying too heavily on a single security solution across critical infrastructure creates dangerous vulnerabilities. Organizations may start to consider a more diverse approach to cybersecurity, balancing the benefits of integrated solutions with the risks of over-centralization.
-
The Value of Offline Backups and Analog Systems: In an increasingly digital world, having offline fallback options can be a lifesaver during major outages. This incident may lead to a renewed appreciation for physical backups and analog systems in critical industries.
-
The Power of Community: The rapid response and collaboration within the tech community showcased the incredible problem-solving potential of crowdsourced solutions. This may lead to more formalized channels for community-driven crisis response in the tech world.
-
The Importance of Transparency and Crisis Communication: The way companies communicate during a crisis can significantly impact public perception and trust. This incident will likely lead to a reevaluation of crisis communication strategies in the tech industry.
-
The Need for Better Failsafes: This incident highlights the need for better failsafe mechanisms in critical software. Future security solutions may incorporate more robust checks and balances to prevent similar widespread failures.
Looking Ahead: The Future of Cybersecurity
As we move past this crisis, it’s clear that the cybersecurity landscape will never be quite the same. This incident will likely spark a wave of innovation in how we approach software updates, system redundancy, and crisis management in the tech world.
We may see the development of more sophisticated update mechanisms that include multiple layers of verification before implementation. There could be a push for more decentralized security solutions that don’t create single points of failure. The incident might also accelerate the development of AI-driven systems that can more accurately predict the potential impact of updates before they’re deployed.
Furthermore, this event is likely to influence regulatory discussions around cybersecurity. We may see calls for increased oversight of cybersecurity providers, particularly those whose products are widely used in critical infrastructure.
The Human Element
Amidst all the technical discussions, it’s crucial not to lose sight of the human element in this crisis. IT professionals around the world worked tirelessly to resolve issues and get systems back online. Their efforts, often under immense pressure and public scrutiny, deserve recognition.
This incident also serves as a reminder of our society’s deep dependence on technology. From air travel to grocery shopping, the disruption caused by this event touched nearly every aspect of daily life for millions of people. It prompts us to question whether we’ve become too reliant on digital systems and whether we need to better prepare for scenarios where these systems fail.
Conclusion: A Wake-Up Call for the Digital Age
The CrowdStrike incident will go down in history as one of the most significant technological disruptions of our time. It serves as a wake-up call, challenging us to rethink our approach to cybersecurity, software updates, and digital infrastructure resilience.
As we move forward, the lessons learned from this event will undoubtedly shape the future of technology and cybersecurity. It’s a stark reminder that in our rush to secure our digital world, we must be cautious not to create new vulnerabilities in the process.
For those of us in the tech world, this event is both a challenge and an opportunity. It challenges us to build more robust, resilient systems that can withstand unforeseen issues. It challenges us to think more critically about the potential consequences of our innovations. And it provides an opportunity to reimagine cybersecurity for the modern age.
As we emerge from this crisis, let’s carry these lessons with us. Let’s strive to create a digital world that’s not just more secure, but also more resilient, more transparent, and better prepared for the unexpected. After all, in the ever-evolving landscape of technology, the next big challenge is always just around the corner. Our job is to be ready for it.